Demo Work for Computer Vision Tasks in Autonomous Driving Team(In progress)
Vehicle Detection
The first thing to know is:
(1) The input is a batch image, of which the shape is (m, 608, 608, 3)
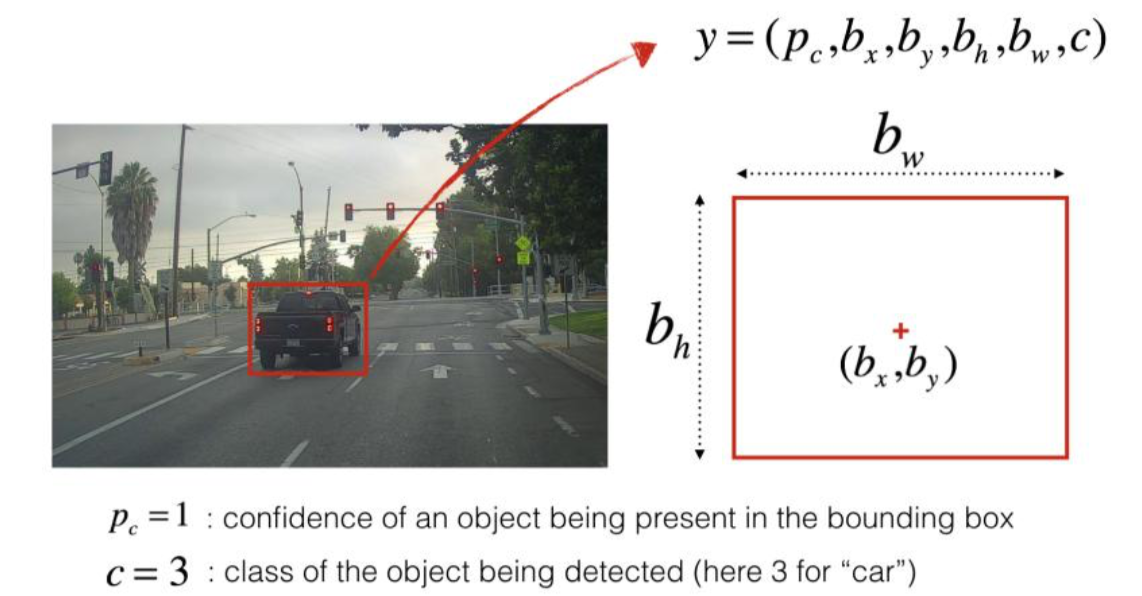
(2) The output is a list of boundingboxes containing the recognition class, each boundingbox has a number (Pc, bx, by, bh, Bw,c), if c expands to 80-dimensional vector, each bounding box will have 85 digits I use 5 anchor boxes, so the general flow of the algorithm is this:
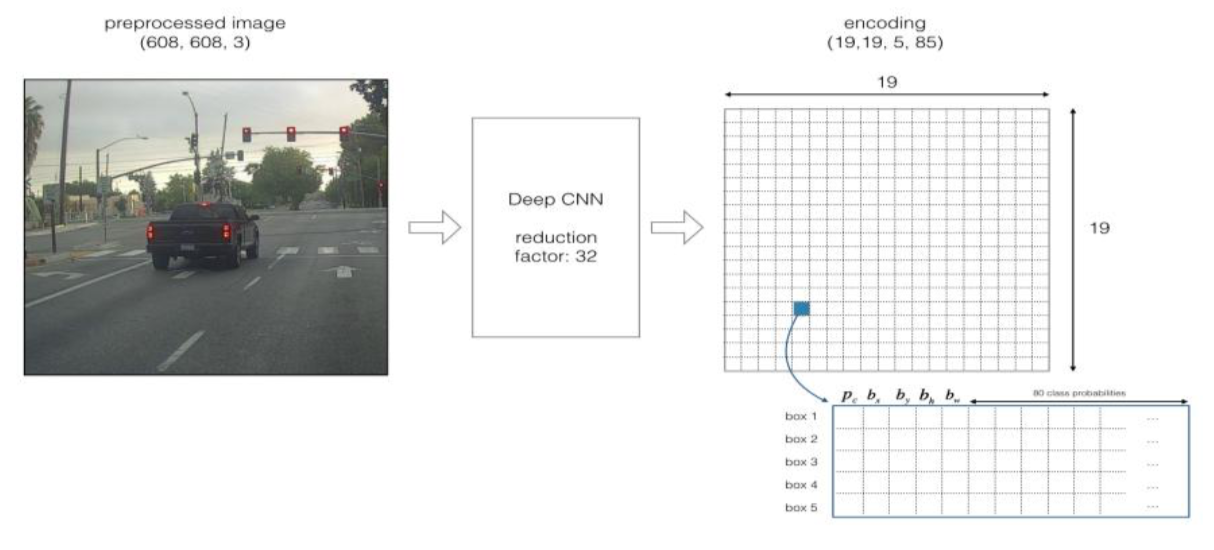
IMAGE(m,608,608,3)—>DEEP CNN —>ENCODING(m,19,19,5,85) The following is the case of ENCODING encoding:
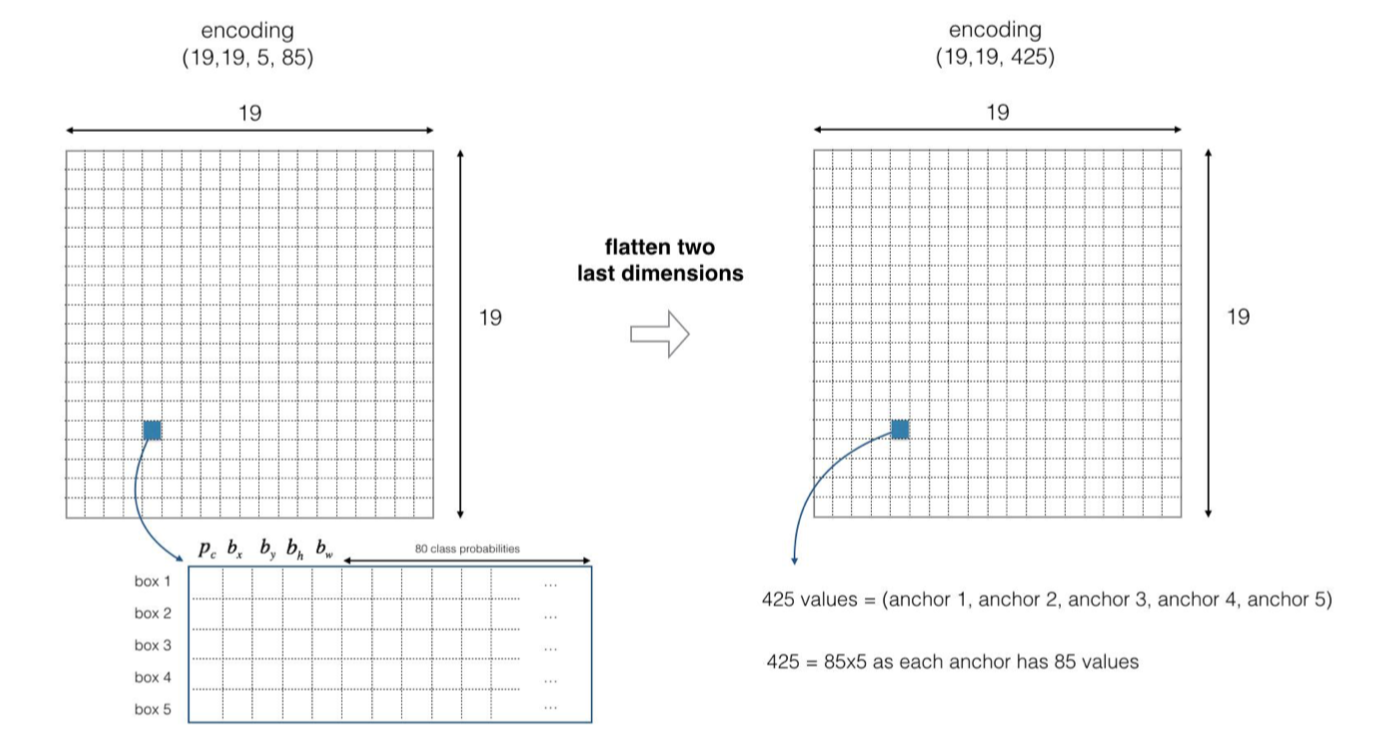
If the object's center/mid point is inside the cell, the cell is responsible for identifying the object. Because we used 5 anchor boxes, each cell (19 × 19 cells) encodes 5 anchor boxes. Anchor boxes are defined by height and width. For the sake of simplicity, we flatten the last two dimensions of the code (19, 19, 5, 85), so the output of DEEP CNN becomes (19, 19, 425),
Now, for each box (each cell), we will calculate the following elementwise product and extract the probability that the box contains a class, as follows:
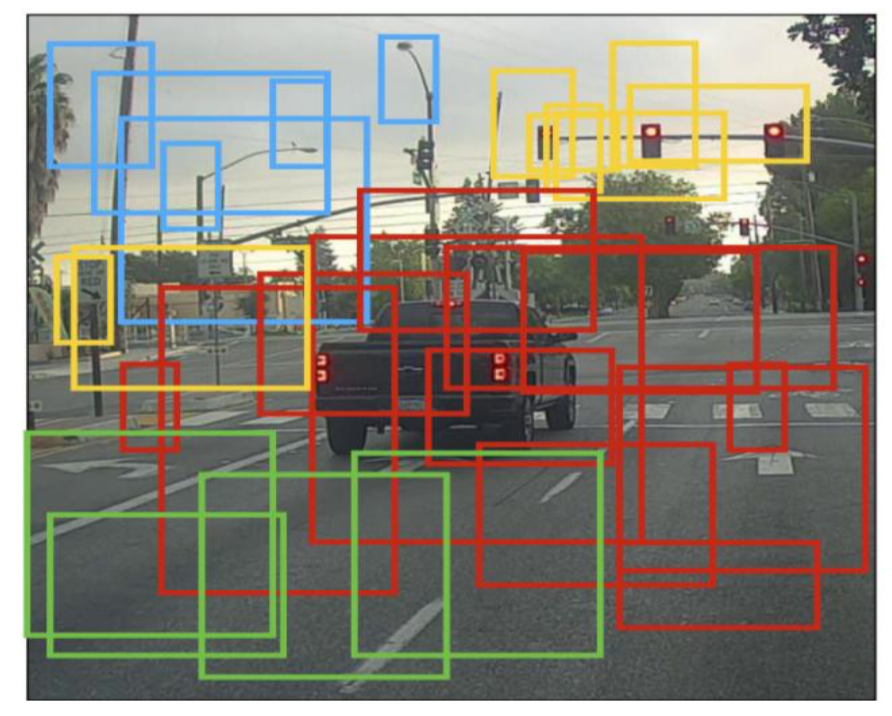
Each cell will output 5 anchor boxes. In general, observe an image (a forward propagation) that requires prediction. 19×19×5=1805 anchor boxes, different colors represent different classifications. In the above figure, only the high probability anchor boxes guessed by the model are drawn, but the anchor boxes are still too much, we hope that the output of the algorithm is more There are fewer anchor boxes, so this will use non_max_supppression, the specific steps are as follows:
(1) Discard the low probability of anchorboxes (meaning, anchorboxes are not so confident to determine this class)
(2) When several anchorboxes overlap each other and detect the same object, select only one anchorbox