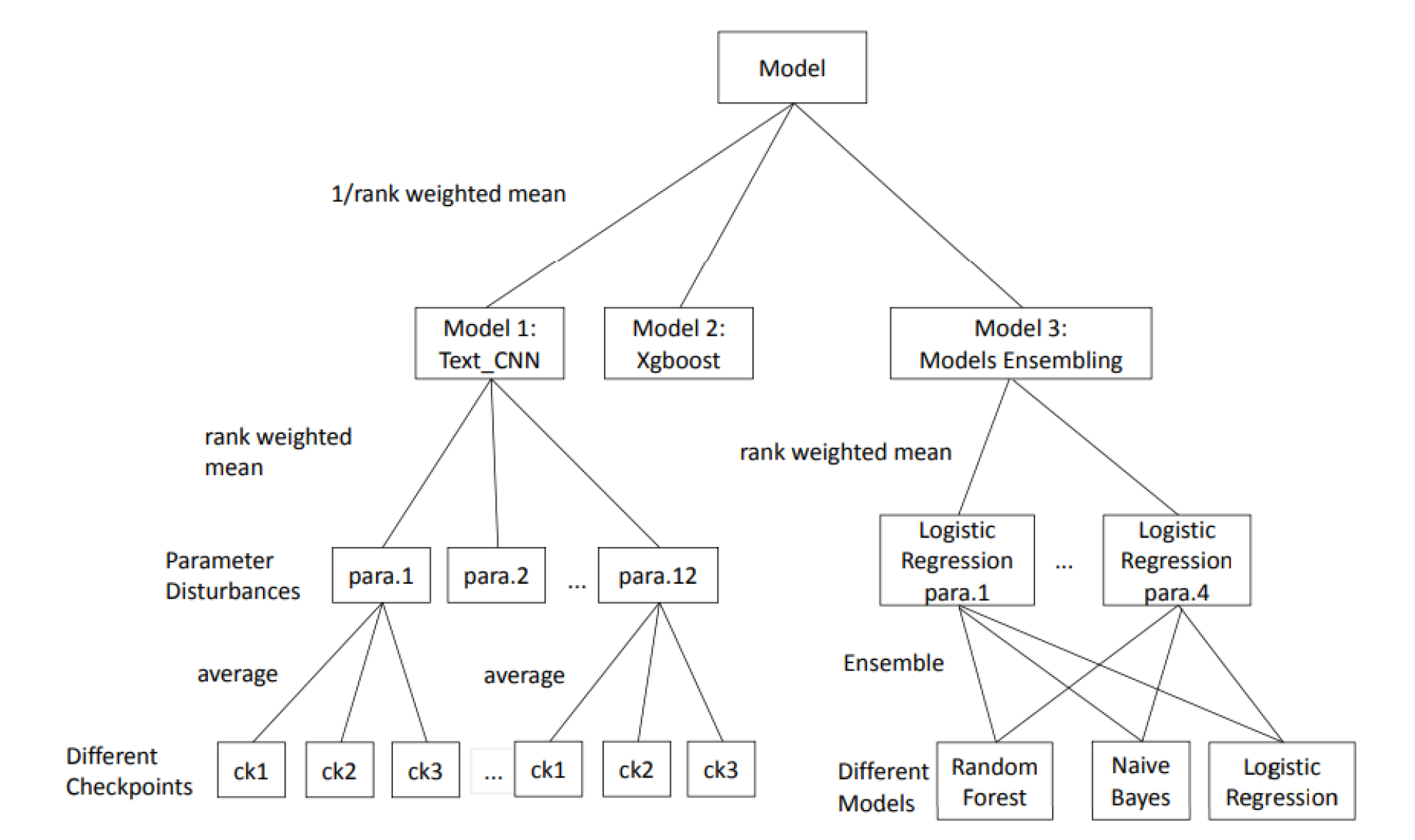
Ensemble-based Improvement on Multiple Models for Text Classification
Intro
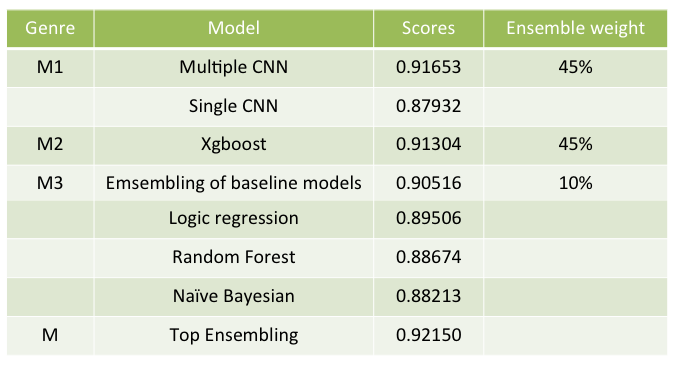
For this project, in order to build a model for text classification to recommend selected articles for Chinese, I compare performances on multiple models such as CNN, Xgboost, logistic regression etc. with ensembling. The project aims to predict the probability of the given text piece belonging to the specific category (binary). Our goal is to train a classification model to predict the category of the given text. The main model I tested was CNN with great improvement combined with xgboost ensemble. However, ensemble of logistic regression did't help a lot.
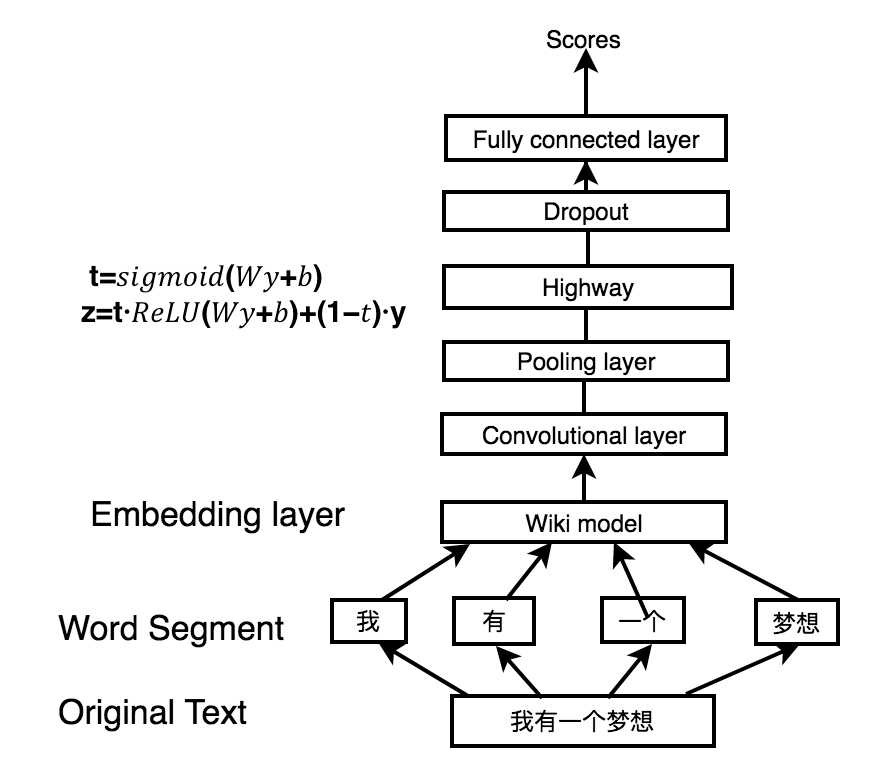
Before constructing different models, I use jieba to segment the text into words. I used word2vec to train on wiki model and apply a three-layer neural network to implement word embedding. This wiki model serves as a language probilistic model to predict the next word. By previous word, we use n-gram to model, which basically take the previous several words to predict.
CNN Classification
Ensemble